B-Trees
B-Trees are used to store very large dictionaries. They allow searches, insertions, and deletions in logarithmic time. A B-Tree node may have up to a few thousand nodes. Since B-Trees have very high branching factor, the tree tend to be bushy compared to red-black tree. They do not require rebalancing operations like rotations. But as more and more insertions happen, the nodes cannot accommodate them. So, more nodes must be added to handle insertions. When deletions take place, it leads to some wastage of storage space. To handle both situations, B-Tree nodes are restructured by splitting and merging. Splitting of a node occurs more and more keys accumulate for room at the node. Similarly, merging occurs when a pair of sibling nodes have lot of vacancies for keys due repeated deletions. Merging reduces height as it may propagate up to the root of tree. Splitting also propagate all the way to the root of a tree causing its height to increase.
Defining a B-Tree
We formalize the definition of a B-Tree specifying the following properties.
- The root is a special node that may have between 2 and M children.
- An internal node may have between M/2 and M children.
- The number of keys stored at a node is one less than the number of children.
- Each leaf node is at the same depth from the root.
- A leaf node stores at most M-1 and at least M/2 elements in sorted order.
The root is the only node in a B-Tree that may be less than half full.
B-Trees do not require rebalancing operations like rotations. But they need nodes to split and merge to handle dynamicity of key insertions and deletions. Insertions increase the number of stored elements and may require splits. Splits may propagate up to the root, causing the tree’s height to increase. On the other hand, the merging of nodes occurs with deletions. It may cause the height of a B-Tree to decrease. The elements appear in sorted order at nodes.
The figure below gives the picture of a B-Tree with M=4.
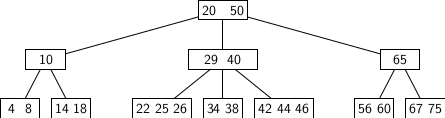
In the figure, the root has two elements: 20 and 40.
- The elements less than 20 can be reached following the leftmost pointer.
- The elements between the range (20, 40) are reachable from the pointer to the right of 20.
- The elements greater than 40 are reachable from the pointer to the right of 40.
Loosely speaking, the two adjacent numbers a, b in an internal node represent an open interval (a, b). Any number x in (a, b), if it exists in the tree, may be found in one of the descendant node u of v which is accessible from the pointer between the numbers a and b.
The minmum number of keys in a tree of height 1 is 1. If we increase height of the tree by 1, the minimum number of keys increases by 2k - 1, where k=⌉M/2⌈. So for different heights of the tree in the minimum number of nodes is:
| Height | Number of keys |
|---|---|
| 1 | 1 |
| 2 | 1+2(k-1) |
| 3 | 1+2(k-1)+2(k-1)k |
| 4 | 1+2(k-1)(1+k+k2) |
In general if height is h then the minimum number of keys will be:
2(k-1)(1+k+k2 + k3 + ... + kh)
Therefore, for a B-Tree with n nodes the height should be at most 1 + logk((1+n)/2)
In the above example, we do not distinguish between items and their keys. Equivalently, an item and its key are are the same.
However, typically in real database implementation, a distinction exists between items and their corresponding keys.
Items are records accessed by providing corresponding primary keys. Therefore, we have two ways of storing items in B-Tree.
- Keys are stored at nodes, and items are stored at external nodes.
- A key and its corresponding item are stored together at the same position.
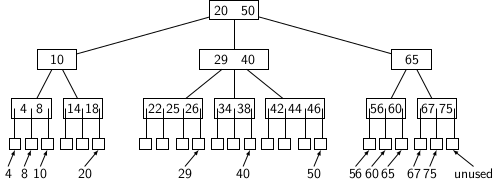
Using different keys and items, we can modify the above example to store data at external nodes, as shown below.
Search: Search operation in a B-Tree is a generalization of the binary search. It combines advantage of a binary search tree with plain binary search on a sorted list. For convenience in description we use the following notation:
- k: key value for search
- n: Current node
The search typically start from root. We try to find a match for k in the local cache of keys maintained at the current node n. If a match is found then we return the node and the index of the matched key. If no match is found in local key cache and n is a leaf, the search terminates without a match for k. Otherwise, we use the left child pointer of the smallest key greater than k in the current node, and recursively perform search from the left child. The pseudo code for searching a k in a given B-Tree appears below.
BtreeSearch(n, k) {
i = 1; // Start from first key position
while (i <= n.count and k >= n.key[i]) //n.count gives the number of keys in node n
i = i + 1; // Locate the smallest key greater than k
if (i <= n.count and k == n.key[i]) // n.key[i] matches k
return (n, i);
if (isLeaf(n))
return NIL // If current node is leaf then key is absent
else
// Recursively search the child node from the pointer to the left of n.key[i]
return BtreeSearch(n.child, k);
}
Insertion: Perform a key search in the given B-Tree for the element. If element is not found the search will terminate at a leaf. If the leaf contains less than M-1 keys then insert the key there. It will require data movements. Some keys may have to be moved to right to make room for the new insertion. If the leaf is full (i.e., it contains M-1 keys) then create a new leaf. Retain the first half the keys in the old leaf and move the second half of the keys to newly created leaf. Push the median to parent and create an extra child link for the new leaf to right of median key pushed to the parent. If parent does not have room, repeat the splitting process again at the parent. The recursice process of splitting may finally split the root and increase the height of the tree by adding a new root.
Essentially, the algoritm for insertion requires two different procedures, namely,
- If the node is full then split the node, place one half of nodes in one and other half in another node of the split.
- If the node is not full then insert the key into the node at proper position by shifting some existing keys to right.
The algorithm uses a bottom up approach for insertion of a new key. It begins search a leaf node where the key belongs. If the node is not full then the insertion is done by shifting other larger keys to the right. However, if the node is full then the node is split into two. The first half of the keys are placed in the original node and a new node is allocated for 2nd half of the keys. The median key is promoted to a place in the parent of the original leaf. It may cause a split in the parent node if the latter is full. The splits can occur recursively all the way to the root. When the root is split a new root is created and the height of the tree increases. The pseudo code of the algorithm for insertion is provided below.
B-Tree-Insert(T, k) {
r = T.root // Start with root
if (r.count == M - 1) {
// The root is full, we have to split it
s = allocate-node();
T.root = s; // New root node
s.leaf = FALSE; // New node will have some children
s.count = 0; // Initialize
s.c[1] = r; // Child of s is the old root node
B-Tree-Split-Child(s, 1, r); // r is split, 1st half of keys goes into r
B-Tree-Insert-Nonfull(s, k); // s is not full
} else
// r is not full, we can insert k into r
B-Tree-Insert-Nonfull(r, k);
}
The algorithm for an insertion into non-full node appears below.
B-Tree-Insert-Nonfull(n, k)
i = n.count;
if (isLeaf(n)) {
// Search for a non existing key will terminate when we are about to fall off from
// the tree. So the node must be a leaf node. Shift keys of this leaf node to the
// right up to the point where the new key k should go
while (i >= 1 and k < n.key[i] ){
n.key[i+1] = n.key[i];
i--;
}
// Put k in its right place and increment the count of keys
n.key[i+1] = k;
n.count++;
} else {
// Find child where new key belongs traversing the tree down to a leaf.
while (i >= 1 and k < n.key[i])
i--;.
// If k belongs to n.child[i], then k <= n.key[i]. We should track back the last
// key (least i) where the inequality is violated, and read that node from disk.
i++;
Disk-Read (c[i])
if ((n.child[i]).count = M - 1) {
// ith child node is full, we will have to split it
B-Tree-Split-Child (n, i, n.child[i]);
// Now n.child[i] and n.child[i+1] are the new children, and key[i] may have been changed.
// Find out if k belongs in the first or the second
if (k > key[i])
i++;
}
//Recursively call this procedure to perform the insertion at right non-full node.
B-Tree-Insert-Nonfull (n.child[i], k);
}
A summary of the overall procedure is provided below for reference.
- Start at the root node and search for the key k to find the place where it can be pushed. Call this node N. A search terminates only at a leaf node when a key, so N must be is a leaf node.
- If N has space for more keys (non-full) shift the larger element to the right, place k, and terminate.
- Otherwise, N is full. Split it two nodes by creating a new node:
- Retain the smaller half the keys in the original node
- Move the larger half of keys to the newly create node.
- Choose the median of the keys and push it to the parent of original node
- If parent is full, it may necessitate a split of parent and split may percolate recursively to root.
- Split the root if required and terminate.
Splitting of the root creates a new root and increases the height of the tree. However, unlike balanced trees, B-Tree does not use rotations to fixup or rebalance the tree.
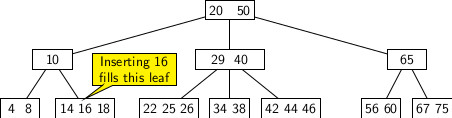
As discussed above, a new insertion into a non-full leaf node simply fills the node with an extra key. For example, if we insert 16 into the B-Tree of figure 1 that appears at the beginning of this blog, the leftmost node becomes full. The figure below illustrates the result of this insertion.
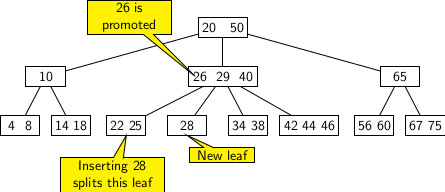
However, suppose we insert 28 to the resulting B-Tree, it splits in third leaf that initially had keys 22, 25 and 26. A new leaf with key 28 is created, and the median key 26 is pushed up to the parent node of the original leaf. The result of this insertion appears below.
We end this blog here, and continue with deletion operation on B-Trees in the next blog.